企業における AI 導入が増加:研究における AI のための防御可能な方法論を構築するにはどうすればよいですか?
その他


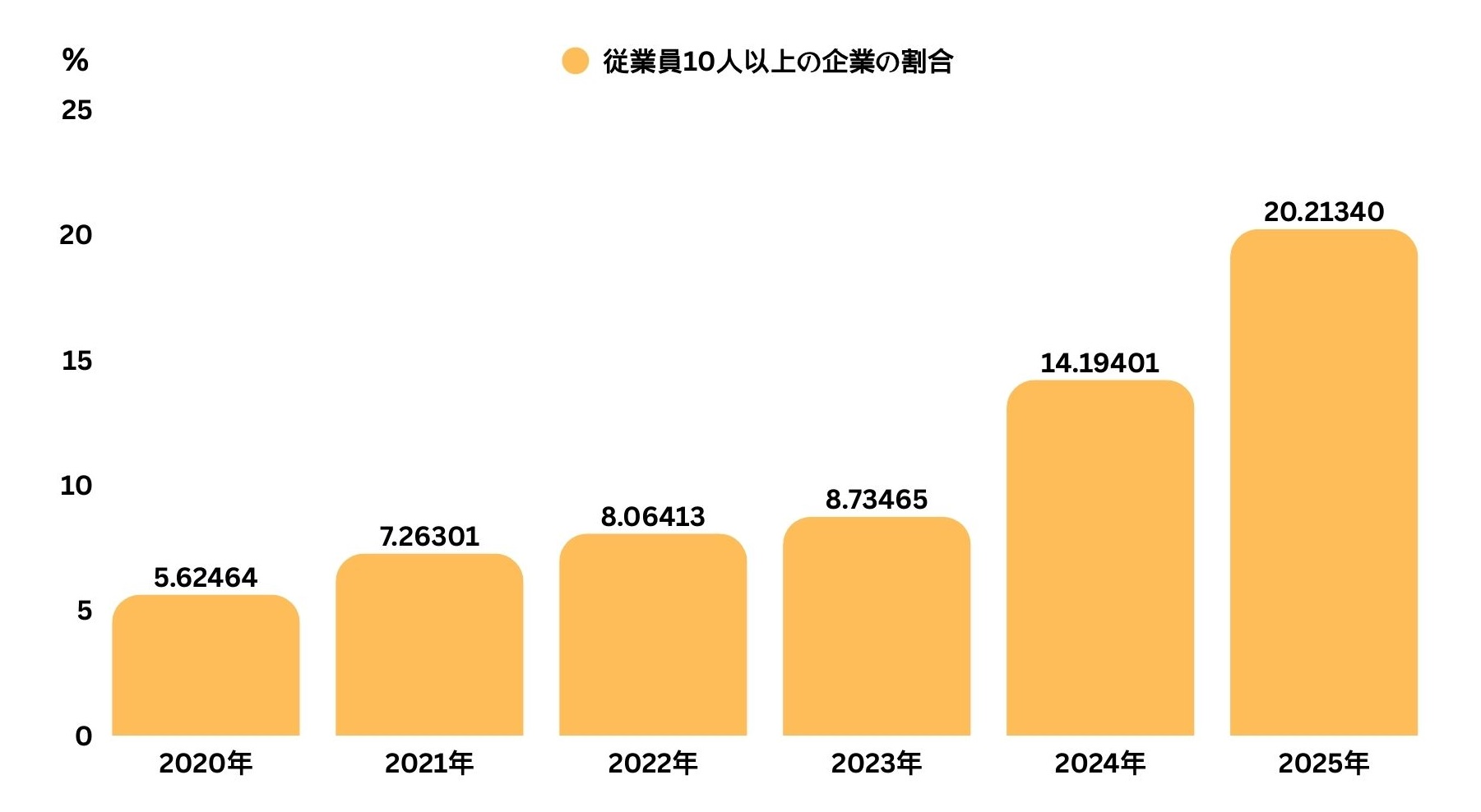
コンテンツワークフローにAIがすでに導入されている場合(たとえ「下書きだけ」であっても)、もはや時代遅れではありませんが、すでに測定可能な波に乗っていることになります。さらに、SDKI Analyticsの推定によると、2026年末までに30%以上の企業がAIを活用すると予想されています。一方、2025年には20.2%の企業がAIを活用していると回答しており、これは2024年の14%、2023年の8.7%から増加しています。
企業レベルのAI導入動向
ソース:OECD
人々はAIに過度の信頼を置くべきではありません。AIは常に正しいとは限らず、幻覚を引き起こすこともあるからです」 —サム アルトマン、 OpenAI CEO
研究におけるAIの急速な利用は、信頼性の問題を引き起こしています。誰もがより早く論文を発表できるようになった今、信頼性こそが差別化要因となることは明らかです。検証を製品機能として捉えるチームは、研究の信頼性維持が急務となる中で、際立つ存在となる可能性があります。そうでないチームは、自信に満ち溢れ、ランキングも上位にランクインする一方で、結果的に誤った論文を発表することになり、結果として評判の低下、論文撤回、そしてクライアントからの反発といった代償を払うことになる可能性があります。
研究におけるAIの役割を理解する
研究におけるAIは、自律的な分析者ではなく、アシスタントとして活用することで最も効果を発揮します。その強みは、発見を加速させることにあります。
- 規制書類のスキャン
- 大規模な文書セットの整理
- 技術資料の要約
- データセット全体で繰り返し現れるテーマを識別します。
主要なAIプロバイダーは現在、高度なツールを複数のソースから構造化された研究形式の出力を統合できるものとして位置付けています。例えば、 OpenAIは自社の「ディープリサーチ」機能を、大量のオンラインソースを検索、分析、統合して包括的なレポートを作成するために設計されたシステムと説明しています。この位置付けは、AIツールが分析ワークフローにますます統合されつつあることを反映しています。さらに、Copilot、Gemini、Claude、Kimiなどの主要なAIモデルもディープリサーチ機能を提供しており、企業がユーザーベースにおいて迅速かつ効率的なリサーチの必要性を認識していることを浮き彫りにしています。ディープリサーチ機能は、研究におけるAIが今後重要な役割を果たすことを示唆しています。
しかし、構造化された出力は検証済みの結論と同義ではありません。AIシステムは確率的なパターン予測に基づいて応答を生成します。以下のことは行いません。
- 一次データを独立して検証します
- 統計の整合性を確認します
- 分析判断に対する法的責任を引き受けます。
したがって、研究におけるAIの役割は明確に限定されなければなりません。AIは情報収集と予備的な統合を加速することができますが、方法論の再構築、独立した検証、あるいは責任ある人間の判断による支援に取って代わることはできません。

AI 支援研究の整合性を確保するための手順は何ですか?
AIツールが調査ワークフローに組み込まれるにつれ、整合性は前提ではなく手順として確立される必要があります。防御可能な方法論には、AI支援による発見と説明責任のある分析判断を区別する明確に定義された手順が必要です。市場調査会社は、レポートが単なるAIによる杜撰なものではなく、アナリストによる厳格なクロスチェックを受けていることを保証する必要があります。
当社は、次のような内容を含む実用的な整合性フレームワークを策定しました。
-
研究範囲を明確に定義する:
AI ツールを使用する前に、研究の課題、関心のある変数、意図する出力を明確にします。曖昧なプロンプトは、多くの場合、曖昧な結論を生み出します。さらに、様々な研究トピックに対して汎用的なプロンプトセットを作成すると、研究方法論に大きなギャップが生じるだけでなく、AIモデルによる幻覚を引き起こす可能性があります。当社のアナリストは、研究ギャップを確実に埋めるために、厳格な人間による監視の下で、非常にターゲットを絞ったプロンプトセットを作成することを推奨しています。
-
一次情報源の階層構造を確立する:
政府のデータベース、規制関連の提出書類、公式開示情報、公式企業レポート、検証済みの機関データなどを優先します。AI生成の要約は、情報源の再構築に取って代わるものであってはなりません。
-
すべての数値的主張を独立して検証する:
AIモデルは「ユーザーバイアス」を満たすために利用される可能性があるため、シミュレーションの影響を受けやすいです。研究におけるAIの信頼性を確保するため、パーセンテージ、成長率、予測、比率は一次データから直接再計算します。再構成なしに定量的な主張を公表することは決して避けるべきであります。
-
引用文献の整合性チェックを実施する:
引用されたすべての情報源が、それぞれの記述内容を直接裏付けていることを確認します。流暢さは正確さの代わりにはなりません。
-
文書化された監査証跡を維持する:
データセットのバージョン、情報源へのリンク、承認のタイムライン、および前提条件に関する注記を保持します。研究の信頼性は追跡可能性にかかっています。読者は情報源へのリンクをたどることができなければならないため、適切な引用が不可欠であります。
これらのステップにより、AIは生産性向上ツールから管理された分析ツールへと進化します。整合性は、個人の監視に依存するのではなく、プロセスに組み込まれます。
AI 主導の研究において人間の説明責任はどれほど重要ですか?
AIシステムの能力が向上するにつれて、人間による監視の役割は拡大する可能性があります。研究におけるAIの信頼性と品質を決定づけるのは、熟練した人間による監視の範囲です。研究の結論には常に、明確に識別可能な人間の責任者が必要です。AIツールは情報の作成、要約、構造化を支援できますが、分析結果に対する法的、倫理的、または専門的な責任を負うものではありません。
防御可能な研究プロセスには以下が必要です。
- 検証を担当する指名されたアナリスト
- 定量的な主張に対する独立した確認
- 出版前の明確な承認
- AIによる支援と最終判断を区別する内部レビュープロトコル
AI モデルは研究において向上していますか?
様々なAIモデルが急速に進化しています。例えば、Open AIのGPT 5.3シリーズ、AnthropicのClaude Sonnet 4.6、Google DeepmindのGemini 3.1 Pro、MetaのLlama 4、xAIのGrok 4.1、DeepseekのDeepseek V.3x、AlibabaのQwenシリーズなどは、幻覚を軽減し、研究の質を向上させるために設計された最新モデルです。
モデルプロバイダーは、幻覚の削減、推論能力の向上、そして情報源の帰属強化に多大な投資を行っています。米国国立標準技術研究所(NIST)は、AIリスク管理フレームワークと生成AIプロファイルを通じて、モデルの進化に伴い、モデルのパフォーマンス、ドキュメント、そして信頼性管理の測定可能な評価を推奨しています。
さらに、主要な AI ラボでは次のようなものも導入されています。
- データベースに出力を基盤とする検索拡張生成(RAG)システム
- ドメイン固有のデータセットでのモデルの微調整
- 引用と閲覧機能が組み込まれています
- 障害モードをテストするためのガードレールとレッドチーム
これらの傾向は、技術的な進歩は著しいものの、改善されたモデルでは特定の種類のエラーが軽減されるだけで、新しいエラーが導入されるため、認識論的リスクが排除されないことを示しています。
- 洗練された出力における過信バイアス
- 完全な捏造ではなく、微妙なデータの誤解
- 引用ドリフト(参照されているが、主張と正確に一致していない情報源)
- 論理的に見えるがニュアンスを圧縮したモデル推論
SDKI Analyticsは、企業間でAI導入が加速しているものの、ガバナンスの成熟度にはばらつきがあると指摘しています。この差は、モデルの能力そのものよりも重要です。たとえ幻覚発生率が半減したとしても、AIを活用した出版の規模はより速いペースで拡大しています。2026年末までに30%以上の企業がAIを利用すると予想され、その割合がさらに増加すると予測されることで、AIへのエクスポージャー全体に対するリスクは増大します。
言い換えれば、分母(コンテンツ量)は分子(精度向上)よりも速いペースで増加しています。これは、信頼性の規律が依然として競争上の差別化要因であることを意味します。したがって、高度なモデルは標準化されるでしょうが、検証文化はおそらく標準化されない可能性があります。そして、長期的な信頼はまさにそこで構築され、企業はリサーチサービスを差別化できるのです。
世界的な AI ポリシーは AI 研究にとって何を意味するのですか?
AI 研究は、政府のガイダンス、国の枠組み、そして一部の地域では拘束力のある規制を通じて、組織外で期待がますます設定される世界へと移行しつつあります。
- 日本は「ガイドライン重視」のガバナンスの明確な例です。経済産業省と総務省は、AIのライフサイクル全体にわたる企業による実務的な導入を明確に目的としたガイドラインを統合し、AIビジネスガイドライン(およびその後の改訂版)を作成しました。研究チームにとって、これは組織がより明確な社内規則、ガバナンス構造、そして責任ある利用規律を実践するよう促すため、重要です。
- さらに、アジア太平洋地域では、シンガポールの IMDA が生成 AI に特化したガバナンス ガイダンスを公開し、GenAI システムを導入する組織が実装可能な制御として位置付けています。
- 一方、オーストラリアはガードレール方式を採用しています。政府は、安全で信頼性の高いAIの開発と展開を導くことを目的とした自主AI安全基準(10のガードレール)を発表しました。
- 韓国も、より正式な統治姿勢へと移行しています。同国政府は、包括的な AI フレームワーク (AI 基本法) とその実施タイムラインを示しており、主要なアジア太平洋経済圏全体で期待がいかに急速に高まっているかを裏付けています。
- ヨーロッパでは、EUのAI法が、段階的な義務を伴うリスクベースの規制アプローチの最も明確な例となっています。研究機関にとって重要なのは、透明性、トレーサビリティ、そしてガバナンスが運用環境の一部になりつつあるということです。
研究ワークフローにおける AI について企業は何を言っているのですか?
重要な問題は、企業が実際のワークフローでAIをどのように活用しているかを実際に公開しているかどうかです。特に研究開発重視の分野や業務改革においては、多くの企業がAIを積極的に活用しています。
- 自動車の研究開発において、Toyota Research Instituteは、プロセスの早い段階でエンジニアリングの制約を統合することで車両設計ワークフローをサポートするために使用される生成 AI 技術を公開しました。
- エンタープライズ/ITワークフローにおいては、Fujitsuがコアシステムの更新時間を短縮する生成AIアプリケーション(ワークフロー高速化の事例)を公開しました。
- ライフサイエンスの研究開発において、Rocheは AI と機械学習を使用して医薬品の発見におけるデータ分析と予測を強化することを検討してきました。
- ガバナンスの姿勢については、Microsoftは日本における責任ある AI ガバナンスに関する公式の見解を発表しました。
これらの例は、大規模な組織が監視と説明責任を大規模に運用する方法を示しています。
アナリストの視点: 研究における AI はどのように SDKI 分析を支援しましたか?
アナリストの観点から見ると、リサーチにおける差別化要因は、その手法の妥当性にあります。SDKI Analyticsでは、アルツハイマー病治療薬市場を評価するにあたり、AIを活用し、米国、EU、日本における規制当局の発表を精査し、臨床段階のパイプライン開発を整理しました。ただし、市場規模の推定と予測モデルは、FDA承認データ、EMAへの申請書類、臨床試験登録簿、国家医療費データベースといった一次情報源のみに基づいて構築しました。これにより、当社が誇るリサーチの信頼性を維持することができました。
さらに、それぞれの収益推定は、有病率、治療適格性の想定、価格ベンチマーク、そして償還方針に基づいて三角測量されました。AIの活用はパターンの顕在化に役立ちましたが、市場における結論を導き出すことはできませんでした。
研究における AI の使用事例:
研究ワークフローにおける AI の運用上の影響を把握するために、SDKI Analytics は、ヘルスケア、産業技術、半導体の各分野にわたる最近完了した 30 件の市場調査レポートを対象に内部評価を実施しました。
目的は、市場規模の評価、予測、検証などのコア分析段階が引き続き人間主導であることを維持しながら、従来のアナリスト主導の調査ワークフローと AI 支援による発見ワークフローを比較することです。
この分析では、定量モデリング開始前にアナリストの多くの時間を費やす初期段階の発見、ドキュメントの集約、データセットの準備タスクに特に焦点を当てました。
研究ワークフローの比較:AI統合前と統合後
|
研究ワークフロー段階 |
AI導入前のアナリストワークフロー |
AI支援ワークフロー |
観測された効率の変化 |
|---|---|---|---|
|
規制情報スキャン(FDA、EMA、METIなど) |
複数の規制ポータルとプレスリリースを手動で検索 |
AIを活用した規制発表のスキャンとクラスタリング |
発見時間を約55-65%短縮 |
|
文献の集約と二次研究の編集 |
アナリストはジャーナル記事、ホワイトペーパー、企業の開示情報を手作業で収集します |
AIを活用した関連文書の検索と要約 |
コンパイル時間を約50-60%短縮 |
|
競争環境マッピング |
断片化された情報源から企業と製品ポートフォリオを手動で特定する |
企業名や製品名などの自動抽出 |
企業識別が約40-50%高速化 |
|
技術傾向の特定 |
アナリストは、業界の出版物全体で繰り返し登場するテーマを手作業で特定します。 |
大規模な文書セット全体にわたる AI 支援パターン認識 |
傾向検出が約45-55%高速化 |
|
モデリングのためのデータセットの準備 |
アナリストは市場指標と生のデータセットを手動でまとめる |
定量モデリング前のAI支援データセット構造化 |
準備が約35-45%速くなる |
ソース: SDKI Analytics
市場レポート開発における時間配分
内部評価では、AI 支援検出ツールの導入前と導入後のアナリストの時間配分も比較しました。
|
レポート開発段階 |
AI統合前のワークフロータイムシェア |
AI支援ワークフロータイムシェア |
|---|---|---|
|
発見と二次調査 |
35-40% |
15-20% |
|
データセットの準備と構造化 |
20-25% |
15-20% |
|
定量モデリングと予測 |
20-25% |
25-30% |
|
検証、三角測量、およびソース検証 |
10-15% |
20-25% |
|
編集レビューとレポートの構成 |
10-15% |
10-15% |
ソース: SDKI Analytics
この変化は、研究における AI が主に発見時間を圧縮し、アナリストが検証、三角測量、分析解釈にさらに多くの労力を割けるようになることを示しています。
よくある質問:
AI の導入が増えるにつれて、研究の信頼性がなぜより危険にさらされるのですか?
AIツールがコンテンツや研究ワークフローに組み込まれるにつれて、アウトプット量は大幅に増加します。モデルは進化していますが、依然として信頼性は高いものの不正確な情報を生成する可能性があります。より多くの組織が草稿作成、要約、分析にAIを活用するようになると、未検証の主張が論文発表に含まれる可能性が高まります。構造化された検証プロセスがなければ、信頼性リスクは大規模に増大します。
新しい AI モデルは、研究で AI を使用する際に幻覚を排除できますか?
新しいAIモデルは、推論、検索システム、そして情報源のグラウンディングの改良を通じて幻覚を軽減するように設計されています。しかし、認識論的リスクを完全に排除できるモデルはありません。幻覚は減少するかもしれませんが、データの微妙な解釈ミス、引用のずれ、あるいは自信過剰な要約などは依然として発生する可能性があります。研究の誠実性を確保するためには、人間による検証が依然として不可欠です。
研究に AI を使用する際に、研究の信頼性を保護するために企業が実行できる実際的な手順は何ですか?
組織は、AI支援による論文作成と定量モデリングを分離し、すべての主張を一次データセットに紐付け、ソースバージョンを文書化し、出版前に構造化された信頼性レビューを実施する必要があります。社内に信頼できる情報源のリポジトリを構築し、監査可能な調査証跡を維持することは、AI支援ワークフローにおける重要な安全策です。
研究チームはどのように AI を責任を持って使用すべきですか?
2026年における研究における責任あるAI活用とは、AIを真実の源泉ではなく、分析アシスタントとして扱うことを意味します。チームはAIを用いて情報を整理し、パターンを特定する必要がありますが、すべての予測、統計、結論は、規制当局への提出書類、政府のデータセット、公式出版物などの検証済みの一次情報源から再構築する必要があります。
透明性は AI 支援研究に対する信頼を高めるですか?
はい。研究が公的に検証可能なデータセットに基づいていることを明確に開示し、検証プロセスを説明することで、機関の信頼を高めることができます。AIが飽和状態にある環境において、透明性は方法論の厳密さを示すものであり、信頼できる研究機関と、正確性よりもスピードを優先する機関を区別する上で重要です。